Qui n’a pas rêvé de pouvoir surveiller de près l’activité de ses partitions IBM i afin de :
- Prévenir les problèmes avant qu’ils n’arrivent,
- Comprendre et adapter les ressources disponibles (CPU, mémoire, disque …) pour ne pas en gaspiller,
- Visualiser en temps réels des données opérationnelles (nombre de commandes, incident sur une ligne de production, nombre d’articles produits sur une chaîne …)
Dans cet article, nous allons explorer l’intégration de l’IBM i dans une stratégie de monitoring et d’observabilité à base de solutions Open Source bien connues du reste de l’IT. Avec l’apport de plus en plus de solutions Open Source dans nos environnements, l’IBM i s’intègre plus que jamais dans le système d’information.

Quelles briques Open Source allons-nous explorer ?
- Grafana : C’est la couche de visualisation des données (métriques et logs provenant de diverses sources de données)
- SimpleJson exporter IBM i: pour exporter des métriques IBM i en temps réel
- Prometheus: pour stocker l’historique des métriques afin d’en conserver une trace dans le temps
- Loki: pour centraliser et historiser les logs (logs Apache, php, cron, Java, custom_log, …)
Côté IBM i, nous allons retrouver :
- Un exporter simpleJson
- Un exporter Prometheus
- Un exporter Loki
A l’extérieur de l’IBM i (mais pourquoi pas sur Power), nous allons retrouver :
- Un serveur Grafana
- Un serveur Prometheus
- Un serveur Loki
- …
Toutes ces briques ne sont pas obligatoires et peuvent être disponibles au sein d’une architecture de machines virtuelles ou de containers.
Pour visualiser un peu mieux l’assemblage de ces briques, voici le schéma d’architecture :


Visualisation dans Grafana
Dans cette architecture, Grafana, c’est l’interface graphique qui sera accessible aux administrateurs / exploitants. Cette application Open Source permet de visualiser des données à partir de nombreuses sources de données différentes grâce à une marketplace intégrée.
Elle offre aussi un grand nombre de possibilités pour visualiser les données que ce soit dans des tableaux ou sous formes de graphiques divers et variés. Les tableaux de bord constitués de ces graphiques sont rafraichis automatiquement à une fréquence donnée ou manuellement à la demande, permettant d’observer les données.
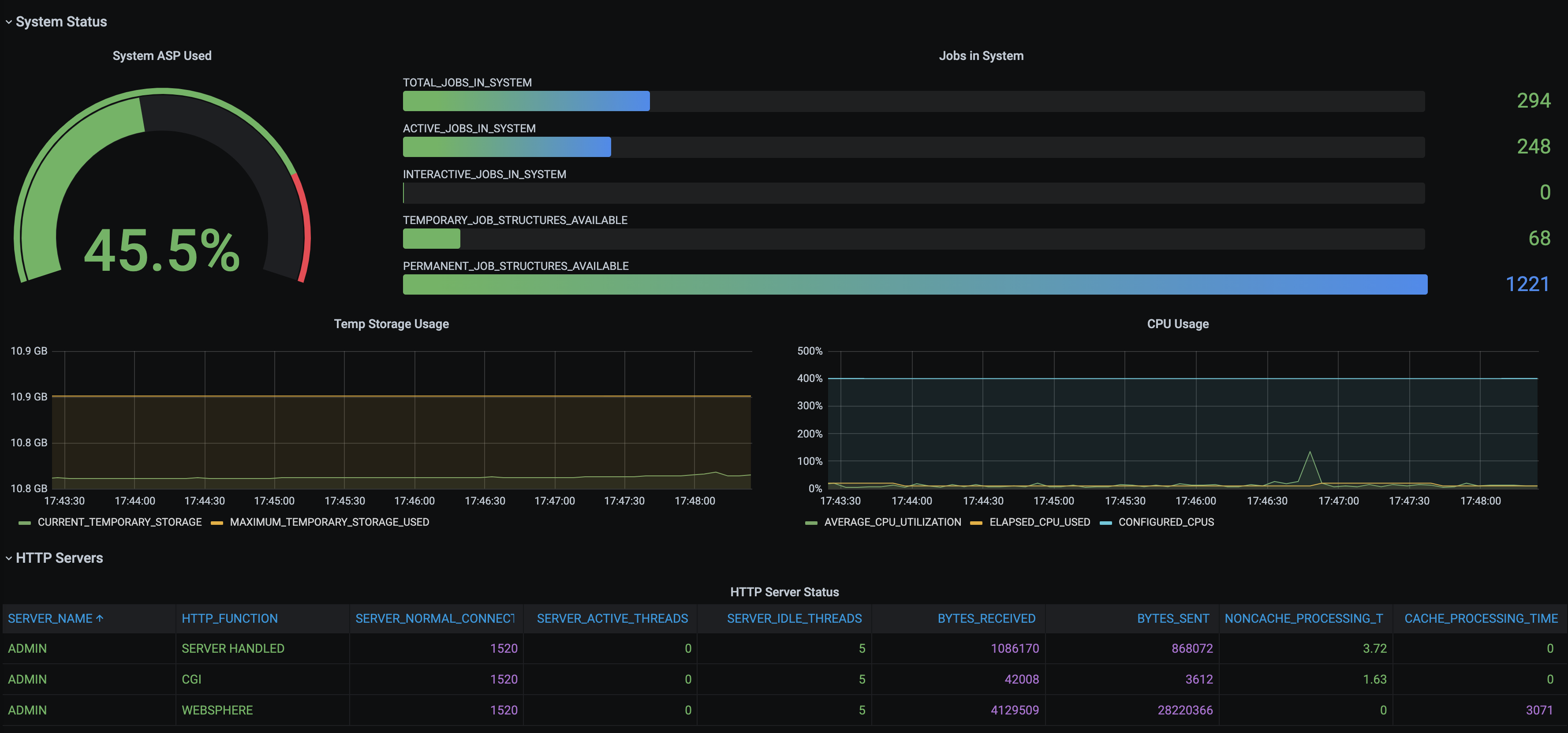
Mais comment alimenter les visualisations ? Ici, nous avons plusieurs possibilités qui s’offrent à nous :
- Des visualisations directes pour un aperçu instantané d’une mesure, d’un état ou d’une donnée sur un système monitoré
- Des visualisations s’appuyant sur des bases de données Time Series permettant de connaitre l’état d’une métrique à un instant choisi (il y a quelques heures, quelques jours …)
Visualisation directe – Grafana-backend – simpleJson exporter
Pour une visualisation en direct des données de l’IBM i dans Grafana, nous pouvons utiliser le projet Open Source grafana-backend qui est une API Web Service en nodeJs (projet disponible ici : https://github.com/IBM/ibmi-oss-examples/tree/master/nodejs/grafana-backend). Cette API respecte le format attendu par une source de données « SimpleJson » de Grafana.
Une fois le grafana-backend démarré sur l’IBM i, nous pourrons ajouter cette source de données dans Grafana et choisir les métriques que l’on souhaite visualiser.
L’API comporte un fichier de configuration personnalisable en fonction de vos besoins. Il est déjà constitué d’un ensemble de métriques pour surveiller l’activité d’une partition IBM i. Mais vous pouvez ajouter vos propres métriques ou requêtes, en utilisant par exemple toutes les possibilités offertes par les IBM i Services ou en vous appuyant sur vos données opérationnelles (commandes, fabrications, incidents…).
Dans certains cas nous sommes intéressés seulement par des données temps réels, mais il est parfois intéressant de pouvoir remonter le temps : en cas de crash ou d’incident ; pour avoir une information contextualisée, pouvoir comparer des périodes d’activités, prévenir un incident etc…

Visualisation dans le temps
Prometheus-exporter
Pour des visualisations s’appuyant sur des bases de données Time Series, il faudra commencer par configurer le lien entre l’IBM i et la TSDB (Time Series DataBase) choisie. Ici nous parlerons de Prometheus car elle est particulièrement bien intégrée avec Grafana. D’autres bases de données Time Series (comme InfluxDB) pourraient être alimentées directement depuis l’IBM i.
Pour alimenter Prometheus, un exporter jdbc Open Source est disponible sur : https://github.com/ThePrez/prometheus-exporter-jdbc.
Cet exporter Prometheus fournit une interface pour la collection passive de métriques, utilisant JDBC pour l’accès aux données. Le serveur Prometheus viendra collecter les données nécessaires en s’appuyant sur cet exporter installé et démarré sur l’IBM i à monitorer. A l’instar de grafana-backend, il est possible de personnaliser les métriques à remonter à l’aide d’un simple fichier de configuration dans lequel nous pouvons ajouter nos propres requêtes SQL.

Centralisation des logs
Loki-exporter
Le dernier point évoqué dans cet article concerne la remontée et la visualisation de logs. Pour cela, nous pouvons utiliser LOKI : https://grafana.com/oss/loki/ . Le serveur LOKI est un serveur spécialement conçu pour historiser des logs à la façon d’une base de données Time Series. Le serveur Loki, tout comme Prometheus, est très bien intégré avec Grafana.
Le serveur Loki dispose d’une API REST permettant notamment la remontée de ces logs (https://grafana.com/docs/loki/latest/api/#push-log-entries-to-loki). Concernant l’IBM i, il ne nous reste plus qu’à appeler cette API pour faire remonter chaque log rencontré. CFD-Innovation a créé un traitement nodeJs permettant de configurer les fichiers de logs à surveiller (logs Apache, php, cron, Java, logs applicatives, custom_log, …) afin de faire remonter dans Loki chaque ligne qui arrive dans ces fichiers au moment où elle arrive (n’hésitez pas à nous demander le script).

Gestion des services
Service-commander
Pour orchestrer et centraliser les services tournant sur l’IBM i, nous utilisons et recommandons service-commander (https://github.com/ThePrez/ServiceCommander-IBMi).
Son installation est rapide et facile au travers des packages rpm IBM i. Il suffira ensuite de configurer dans un fichier yaml chacun des services que vous souhaitez voir fonctionner sur votre machine (dans l’exemple de cet article : grafana-backend ; prometheus-exporter-jdbc ; loki-exporter).
Une fois cette opération réalisée, et bien que vos « agents » utilisent différentes technologies (java, node, web …), vous allez pouvoir surveiller leur bonne santé, les arrêter / démarrer individuellement le tout avec une commande unique : « sc start… sc stop… ».
Merci aux travaux et projets de Jesse GORZINSKI sur ces sujets qui aident grandement à une intégration rapide et fiable de l’IBM i dans une stratégie d’observabilité en entreprise, ainsi qu’à Guillaume BONNEAU et Jean Marc SOLIVEAU (Novacel Ophtalmique) dont les besoins ont guidé les recherches et travaux sur le sujet.
